




Perl Example #1
Basic Datatypes - Scalar, Array, and Hash
Basic Datatypes - Scalar, Array, and Hash
About
The Program
This program uses variables of each
of three basic types: scalar, array, and hash. Scalar variables can be numbers
or strings, and the language will understand how to treat the data by the
context of its use. An array is a linear collection of scalar data. A hash, or
associative array, is a built-in data type that will associate a
"key", with a piece of data.
The code presented here demonstrates
how flexible these datatypes can be, such as having arrays that contain numbers
as well as words, and the fact that array sizes can change dynamically. It also
shows how the format of array output can be modified in a print statement using
one of the special forms, "$,".
The output of the perl script shown
in red italics has been interspersed between the Perl code in order to make it
easier to follow what is happening in the program. The full program as well as
the observed output are available as links at the bottom of the page.
#!/usr/bin/perl
#
The first line of the script envokes Perl
#
Use "/usr/bin/perl -w" option for debugging
#
Scalar variables
$var1
= "Hello World";
$var2
= 14.6;
#
Array variables
@arr1
= (0,1,2,3,4);
@arr2
=
("zero","one","two","three","four");
#
Hash variable, or associative array
%hash1
= ("one","Monday","two", "Tuesday","three",
"Wednesday","four","Thursday");
#
Some simple printing examples
print
$var1; # Printing out Scalar Variables
print
(" ",$var2,"\n");
Hello World 14.6
print
(@arr1,"\n"); # Print out the
arrays
print
(@arr2,"\n\n");
01234
zeroonetwothreefour
zeroonetwothreefour
@arr3
= @arr1; # Create a third array and copy
everything
print
(@arr3,"\n");
print
"\n";
01234
print
($arr1[0], "\n"); # Print
specific srray elements (scalar values)
print
($arr2[3], "\n");
print
"\n";
0
three
three
print
(%hash1,"\n"); # Printing
out the full hash array
threeWednesdaytwoTuesdayoneMondayfourThursday
$key
= "two";
print
($hash1{$key}, "\n\n"); #
Print out an element in the hash array
Tuesday
#
Here's where things get kewl...
$arr2[1]
= $arr1[1]; # Working with different
data types
$,
= " "; # Kewlness: Changing
the separator between array elements
print
(@arr1,"\n");
print
(@arr2,"\n\n");
0 1 2 3 4
zero 1 two three four
zero 1 two three four
$,
= ": "; # Change the separator
again
print
(@arr1,"\n");
0: 1: 2: 3: 4:
print
(@arr2,"\n\n");
zero: 1: two: three: four:
print
(%hash1,"\n\n");
three: Wednesday: two:
Tuesday: one: Monday: four: Thursday:
$arr1[4]
= $var1; # Add on at the end of the
array
print
(@arr1,"\n");
0: 1: 2: 3: Hello World:
$arr2[7]
= $var2; # Go beyond the array
print
(@arr2,"\n\n");
zero: 1: two: three: four:
: : 14.6:
@arr1[3..5]=@arr2[2..4]; # Copy portions of one array to another
$,
= " -> "; # Change
separator again
print
(@arr1,"\n");
0 -> 1 -> 2 ->
two -> three -> four ->
print
(@arr2,"\n\n");
zero -> 1 -> two
-> three -> four -> -> -> 14.6 ->
#
Dealing with Hashing
print
(keys %hash1, "\n"); #Print
out the keys of the hash
three -> two -> one
-> four ->
foreach
$key ( keys %hash1) # Cycle through all
key
{print $hash1{$key};
}
print
"\n\n";
WednesdayTuesdayMondayThursday
$,
= ":";
print
@arr1; # Print array 1, just for
reference
0:1:2:two:three:four:
for
($i=0; $i<7; $i++) # Loop through
all elements in array 1
{ print ($hash1{$arr1[$i]},
"\n"); #Print Hash value if it
exists
}
:
:
Tuesday:
Wednesday:
Thursday:
:
:
Tuesday:
Wednesday:
Thursday:
:
The
Actual Code for Experimentation: ex1.pl
The
Actual Output: ex1.out
Perl Example #2
Simple Matching Operations
Simple Matching Operations
About
the Program
This program demonstrates the use of
some pattern matching operations, as well as a few other new features. The
responses shown in red italics show two possible forms, one if the initial
input is a program in the directory, ex2.pl ,
and the other if it is an invalid input xxx. The
perl function "chomp" allows the user to strip off extra
carriage returns from standard input, which is typically the keyboard. The UNIX
command "ls -l" is run inside the single backquote and the
output is assigned to simple variables of scalar as well as array types.
The pattern matching process is
shown using the match operator, "=~", as well as
the no match approach using "!~". In the second
match process, a "regular expression" is used to set up a pattern. In
general, the user is searching for files that end in the appropriate ".pl"
extender. The pattern looks for spaces on both sides, but does not want to
include that in the actual "tagged" argument (inside the
parentheses). That argument is later referenced as "$1" in
after the match is found.
#!/usr/bin/perl
-w
print
"Enter a file name:";
chomp($fname
= <STDIN>); # File name is read
from standard input (keyboard).
# Chomp removes
any carriage returns from input
Enter a file name: ex2.pl
or xxx
print
"\nLooking for $fname in the following directory:\n";
Looking for ex2.pl
in the following directory:
or
Looking for xxx in the following directory:
$dir_list = `ls -l`; # run the UNIX Command - assign output to a variable print $dir_list,"\n";
or
Looking for xxx in the following directory:
$dir_list = `ls -l`; # run the UNIX Command - assign output to a variable print $dir_list,"\n";
total 31
-rw-r--r-- 1 dhyatt faculty
540 Sep 9 19:02 ex1.out
-rwxr-xr-x 1 dhyatt faculty
1883 Sep 9 11:45 ex1.pl
-rw-r--r-- 1 dhyatt faculty 0 Sep 11 19:50 ex2.out
-rwxr-xr-x 1 dhyatt faculty
1577 Sep 11 19:49 ex2.pl
-rw------- 1 dhyatt faculty
24576 Sep 11 19:49 ex2.pl.swp
-rwxr-xr-x 1 dhyatt faculty
1904 Sep 8 19:13 hello.pl
###
Simple Matches ###
#
Common "if" approach at end of statement using MATCH operator
"=~"
print
"Found file $fname in directory.\n" if $dir_list =~ $fname;
Found file ex2.pl in
directory. ( or no response... )
#
Familiar "if-else" construction using NO-MATCH operator
"!~"
if
($dir_list !~ $fname)
{
print "Sorry... No $fname in this
directory.\n\n";
}
else
{
print "Got a Match!\n\n";
}
Got a Match!
or Sorry... No xxx in this directory.
###
Advanced Matching Capabilities ###
#
Create an Array using the directory listing
@dir_array = `ls -l`;
print
"Here is the directory again:\n";
print
@dir_array, "\n";
Here is the directory again:
total 31
-rw-r--r-- 1 dhyatt faculty
540 Sep 9 19:02 ex1.out
-rwxr-xr-x 1 dhyatt faculty
1883 Sep 9 11:45 ex1.pl
-rw-r--r-- 1 dhyatt faculty 0 Sep 11 19:50 ex2.out
-rwxr-xr-x 1 dhyatt faculty
1577 Sep 11 19:49 ex2.pl
-rw------- 1 dhyatt faculty
24576 Sep 11 19:49 ex2.pl.swp
-rwxr-xr-x 1 dhyatt faculty
1904 Sep 8 19:13 hello.pl
print
"Here are the perl programs:\n";
$max_lines
= $#dir_array; # The "$#" returns highest array
index
$pattern
= '\s+(\w+\.+pl)\s'; #Define a pattern
using "regular expressions"
#
Meaning "\s+" - at least one or more spaces or tabs
# "\w+" - at least one or more
alpha-numeric characters
# "\.+" - a period or dot
# "pl" - the proper
"pl" extender
# "\s" - a trailing space
$j=0;
for
($i=0; $i <= $max_lines; $i++) # Loop through all lines
{
if ($dir_array[$i] =~ $pattern)
{print $1, "\n";
$perlprogs[$j] = $1;
$j++;
}
}
Here are the perl
programs:
ex1.pl
ex2.pl
hello.pl
ex1.pl
ex2.pl
hello.pl
print
"The program names are also stored in an array: ";
$,
= ", ";
print
@perlprogs;
print
"\n";
The program names are also
stored in an array: ex1.pl, ex2.pl, hello.pl
Perl Example #3
Working with Files in Perl
Working with Files in Perl
About
the Program
The following program demonstrates
some of the power of Perl when working with files. It shows two techniques for
reading in files. The first method is called "slurping" where the
entire file is read into memory, and the second is a more standard approach where
one line is read in at a time. This example also shows how various file
attributes can be accessed from the Perl code.
In addition to file operations, the
program also uses some additional pattern matching and substitution operations.
With the second file, the program will use the translate function "tr"
to translate input lines to all uppercase letters as well as the substitution
operator "s" to relace characters and strings. Many of these
operations work with "$_", the default scalar variable in
Perl. In most perl programs, this variable is not written out in the code, but
is just understood to be the operand.
#!/usr/bin/perl
-w
#Experimenting
with files
print
"Enter filename:";
chomp($fname
= <STDIN>);
##
Open a file. If unsuccessful, print an
error message and quit.
open
(FPTR,$fname) || die "Can't Open File: $fname\n";
#
First Technique: "Slurping"
#
This approach reads the ENTIRE file into memory
#
Caution... This is not a good method for BIG files!!!
@filestuff
= <FPTR> #Read the file into an
array
print
"The number of lines in this file is ",$#filestuff +
1,"\n";
print
@filestuff;
Enter filename:
temp.txt
The number of lines in this file is 4
This is my file,
It's all full of text.
Upcase the chars,
And screw up what's left.
The number of lines in this file is 4
This is my file,
It's all full of text.
Upcase the chars,
And screw up what's left.
close
(FPTR); #Close the file
##
Some other useful capabilities
##
Testing file attributes:
print
"Enter another filename:";
chomp($fname
= <STDIN>);
if
(-T $fname) # Check if it's a textfile,
and how old
{
print "File $fname is textfile.
";
print "It was modified ", int(-M
$fname), " days ago.\n";
open (FPTR,$fname) || die "Sorry. Can't Open File: $fname\n";
}
elsif
(-B $fname) # Check if it's a binary
file, and some other stuff
{
print "File $fname is executable.\n"
if (-x $fname);
print "This file is ", -s $fname,
" bytes.\n";
die "Since it is Binary file, we will
not try to \"upcase\" this file.\n";
}
else
{die "File $fname is neither text nor
binary, so it may not exist. \n" ;
}
|
Enter another filename:
window1
File window1 is executable. This file is 27141 bytes. Since it is Binary file, we will not try to "upcase" this file. |
|
Enter another filename: temp.txt
File temp.txt is textfile. It was modified 2 days ago. |
##
Open a file for writing. Note UNIX-like
I/O redirection symbol, ">".
open
(OUTFILE, ">upcase.txt") || die "Can't oupen output
file.\n";
##
Better approach for large files... Work with just current input line.
while
(<FPTR>) # While still input lines
in the file...
{
print "1. ",$_; # The symbol "$_" is the default
variable, the current
# input from file. Note: "$_" is assumed if left out.
tr/a-z/A-Z/;
# Translate all lower case letters to uppercase letters
# in the default variable.
print "2. ", $_;
s/A/@/g;
# More substitutions: All
"A" chars become "@" signs.
print"3. ", $_;
s/UP/Down/g;
# All "UP" words are replaced by the string "Down"
print "4. ", $_;
$pattern = '\sF(.*)L'; # Meaning of Regular Expression:
# \sF - starts with
a and capital F
# .* - some stuff in between
# L - Has a capital L in it
# The parentheses "mark" the stuff
in between
print " Match value: ", $1, "\n" if
(/$pattern/);;
s/$1/*/g if $_ =~ $pattern; # Substitute
"*" for the marked pattern,
# but anywhere within the line.
print "5. ", $_, "\n";
print OUTFILE $_; # Print default variable to OUTFILE.
}
close
(FPTR); # Close the other two files
close
(OUTFILE);
1. This is my file,
2. THIS IS MY FILE,
3. THIS IS MY FILE,
4. THIS IS MY FILE,
Match value: I
5. TH*S *S MY F*LE,
1. It's all full of text.
2. IT'S ALL FULL OF TEXT.
3. IT'S @LL FULL OF TEXT.
4. IT'S @LL FULL OF TEXT.
Match value: UL
5. IT'S @LL F*L OF TEXT.
1. Upcase the chars,
2. UPCASE THE CHARS,
3. UPC@SE THE CH@RS,
4. DownC@SE THE CH@RS,
5. DownC@SE THE CH@RS,
1. And screw up what's left.
2. AND SCREW UP WHAT'S LEFT.
3. @ND SCREW UP WH@T'S LEFT.
4. @ND SCREW Down WH@T'S LEFT.
5. @ND SCREW Down WH@T'S LEFT.
2. THIS IS MY FILE,
3. THIS IS MY FILE,
4. THIS IS MY FILE,
Match value: I
5. TH*S *S MY F*LE,
1. It's all full of text.
2. IT'S ALL FULL OF TEXT.
3. IT'S @LL FULL OF TEXT.
4. IT'S @LL FULL OF TEXT.
Match value: UL
5. IT'S @LL F*L OF TEXT.
1. Upcase the chars,
2. UPCASE THE CHARS,
3. UPC@SE THE CH@RS,
4. DownC@SE THE CH@RS,
5. DownC@SE THE CH@RS,
1. And screw up what's left.
2. AND SCREW UP WHAT'S LEFT.
3. @ND SCREW UP WH@T'S LEFT.
4. @ND SCREW Down WH@T'S LEFT.
5. @ND SCREW Down WH@T'S LEFT.
Perl Example #4
Using Simple Perl Functions
Using Simple Perl Functions
About
the Program
This program demonstrates the use of
several simple functions in Perl. The first function used is "split"
which breaks a string into array elements depending upon the string used as a
marker for the split process. In the example, entries from the passwd
file are selected, and then the fields are separated using the colon (:)
as a marker. The delimiter used to mark the string are very flexible, and both
the double quote (") and the slash (/) are used in the
splitting examples. The opposite of split is join, but that
function is not demonstrated.
The next function is "pop"
which chops off the highest element from an array, and returns that value.
Naturally, there is a push function, but it is not demonstrated. The sort
command is shown, however.
The final part of the program shows
how to implement the equivalent of a "case statement", since there is
no "switch" command in Perl as there is in C or C++ languages. It
uses the power of matching and regular expressions in order to achieve the same
result.
#!/usr/bin/perl
#
Using Simple Perl Functions
print
"Enter pattern:";
$pattern
= <STDIN>;
Enter pattern: Josh
#
Scan through the passwd file. Create an array of lines with search pattern
@people
= `cat /etc/passwd | grep $pattern`;
print
@people, "\n";
jeddy:8J2fhwdxUqEiM:2626:1999:Joshua
Eddy:/home/atlas2/jeddy:/usr/local/bin/bash
jsarfaty:xMD4HK533Jr/w:2702:1998:Josh Sarfaty:/home/atlas2/jsarfaty:/usr/local/bin/bash
jglasser:a7DEi4IKsVK2k:2707:1999:Joshua Glasser:/home/atlas2/jglasser:/usr/local/bin/bash
jgillon:GARzdVZX.8LNY:2826:1999:Josh Gillon:/home/atlas2/jgillon:/usr/local/bin/bash
jblake:aP9RpObogxMN2:2849:2001:Joshua Blake:/home/atlas2/jblake:/usr/local/bin/bash
jsarfaty:xMD4HK533Jr/w:2702:1998:Josh Sarfaty:/home/atlas2/jsarfaty:/usr/local/bin/bash
jglasser:a7DEi4IKsVK2k:2707:1999:Joshua Glasser:/home/atlas2/jglasser:/usr/local/bin/bash
jgillon:GARzdVZX.8LNY:2826:1999:Josh Gillon:/home/atlas2/jgillon:/usr/local/bin/bash
jblake:aP9RpObogxMN2:2849:2001:Joshua Blake:/home/atlas2/jblake:/usr/local/bin/bash
#
This section manipulates the strings grabbed from the passwd file
$j=0;
for
($i = 0; $i<= $#people; $i++)
{$_ = $people[$i];
# Use "split" to break the string
into separate elements between colons
@passwd_data[0..6]=
split(":"); # Using double
quotes for the delimiter
# This field contains the full name of the
user
print $passwd_data[4];
print "\n";
# Use "split" to break apart first
and last names
@temp = split(/ /, $passwd_data[4]); # Use the slash for a delimiter
# Use the function "pop" to pull
off the last name
$lastnames[$j] = pop(@temp);
#print last name first, then what's left in
@temp (first name)
print $lastnames[$j],", ", @temp ,
"\n\n";
$j++;
}
Joshua Eddy
Eddy, Joshua
Josh Sarfaty
Sarfaty, Josh
Joshua Glasser
Glasser, Joshua
Josh Gillon
Gillon, Josh
Joshua Blake
Blake, Joshua
Eddy, Joshua
Josh Sarfaty
Sarfaty, Josh
Joshua Glasser
Glasser, Joshua
Josh Gillon
Gillon, Josh
Joshua Blake
Blake, Joshua
$,="\n
"; # Change the print separator to
a carriage return
#
Use the "sort" function to sort the array
print
"Sorted by last name: ",sort @lastnames;
print
"\n";
Sorted by last name:
Blake
Eddy
Gillon
Glasser
Sarfaty
Blake
Eddy
Gillon
Glasser
Sarfaty
$,=""; # Reset the print separator to null
#
Emulating the "switch" statement
print
"Do they like Perl?\n";
while
(<>) # Infinite loop requesting
keyboard response
{
$answer = "I don't understand. Type
'Q' to quit";
REPLY:
# Skip other statements at "last REPLY". Exit loop at "goto".
{
# Beginning "y" followed by
possibly "es" at end, and ignore case
/^y(es)?$/i && do { $answer= "Perl is
Kewl!"; last REPLY; };
# Beginning "n" followed by
possible "o", ignore case
/^no?$/i
&& do { $answer =
"What a shame..."; last REPLY; };
# The exact word "maybe", but
ignore case
/^maybe$/i &&
do { $answer = "Let's learn more."; last REPLY; };
# Beginning "q", or the word
"quit", ignoring case. Jump
out of "while"
/^q(uit)?/i &&
do { $answer = "QUIT"; print "Thanks!\n";goto EXIT;
};
}
print $answer, "\n";
print "But, do they like
Perl?\n";
}
EXIT:
print
"Going on....\n";
Do they like Perl? yes
Perl is Kewl!
But, do they like Perl? Y
Perl is Kewl!
But, do they like Perl? nO
What a shame...
But, do they like Perl? maybe
Let's learn more.
But, do they like Perl? sure
I don't understand. Type 'Q' to quit
But, do they like Perl? q
Thanks!
Going on....
Perl is Kewl!
But, do they like Perl? Y
Perl is Kewl!
But, do they like Perl? nO
What a shame...
But, do they like Perl? maybe
Let's learn more.
But, do they like Perl? sure
I don't understand. Type 'Q' to quit
But, do they like Perl? q
Thanks!
Going on....
Perl Example #5
Subroutines and Parameter Passing
Subroutines and Parameter Passing
About
the Program
This program shows five different
subroutines, and explains how several of these deal with parameter passing. The
first subroutine, sub1, does not have passed parameters but uses
some global variables, as well as a local variable declared by using the word
"my". Since this variable has the same name as the global one, it
will take precedence due to the scoping withing the subroutine.
All of the other subroutines, sub2,
sub3, sub4, and sub5, receive a
"flat" array-type parameter list referenced as @_ , and accesses
individual arguments using scalar elements $_[0], $_[1], though. $_[n].
These subroutines show various techniques including return values, mixed
parameter types, and the use of reference pointers.
#!/usr/bin/perl
#
Subroutines, Parameters, and Reference Variables
$var1
= 13; # Global Scalar Variable
$var2
= 51; # Global Scalar Variable
@arr1
= qw(AAA BBB CCC DDD EEE FFF); # Global array
# Uses
"qw" command to quote words
#
SUB1: Shows use of subroutine variable
"$var1" that has same name as the
# global one. The use of "my" forces scoping to
subroutine only.
sub
sub1
{
my($var1) = 99; # Reserved word "my" makes $var1
unique to subroutine
print "
In sub1: Var1 = $var1 Var2 =
$var2 Array1 = @arr1 \n\n";
}
Initial Values:
In main: Var1 = 13 Var2 = 51 Array1 = AAA BBB CCC DDD EEE FFF
Calling sub1: sub1;
In sub1: Var1 = 99 Var2 = 51 Array1 = AAA BBB CCC DDD EEE FFF
In main: Var1 = 13 Var2 = 51 Array1 = AAA BBB CCC DDD EEE FFF
In main: Var1 = 13 Var2 = 51 Array1 = AAA BBB CCC DDD EEE FFF
Calling sub1: sub1;
In sub1: Var1 = 99 Var2 = 51 Array1 = AAA BBB CCC DDD EEE FFF
In main: Var1 = 13 Var2 = 51 Array1 = AAA BBB CCC DDD EEE FFF
#
SUB2: Demonstrates how to pass a scalar
parameter to subroutine. This
# parameter does reference the original
$var1, and will change the value.
# Without preferred scoping using "my", $var3 will also be
known in main.
# The variable @_ represents the full
array of parameters passed.
sub
sub2
{
print "
In sub2: Parms = @_ \n"; #
The full parameter list
$var1 = $_[0]; # Passed scalars are
referenced as $_[0], $_[1], $_[2], ...
$var3 = $_[1];
print "
In sub2: Var1 = $var1 Var2 =
$var2 Var3 = $var3 \n\n";
}
Calling sub2: sub2($var2,88);
In sub2: Parms = 51 88
In sub2: Var1 = 51 Var2 = 51 Var3 = 88
In main: Var1 = 51 Var2 = 51 Var3 = 88 Array1 = AAA BBB CCC DDD EEE FFF
In sub2: Parms = 51 88
In sub2: Var1 = 51 Var2 = 51 Var3 = 88
In main: Var1 = 51 Var2 = 51 Var3 = 88 Array1 = AAA BBB CCC DDD EEE FFF
#
SUB3: Demonstrates how to return a
scalar from a subroutine call. The
# module modifies a subrange of @arr1,
and returns number of changes.
sub
sub3
{ my ($diff);
print "
In sub3: Parms = @_ \n";
# Print out parameter string
print "
In sub3: ";
for ($_[0]..$_[1]) # Step through subrange, one by one
{
print $_, ". ",$arr1[$_],
" "; # Default variable is
current counter
$arr1[$_] = $arr1[$_]."XX"; # Concatenate operator is "."
(dot)
}
print "\n";
print "
In sub3: @arr1 \n";
$diff = $_[1] - $_[0] + 1; # Determine number of items used
return $diff; # Assign return value
to subroutine
}
Calling sub3: $var2 = sub3(2,4);
In sub3: Parms = 2 4
In sub3: 2. CCC 3. DDD 4. EEE
In sub3: AAA BBB CCCXX DDDXX EEEXX FFF
In main: Var1 = 51 Var2 = 3 Array1 = AAA BBB CCCXX DDDXX EEEXX FFF
In sub3: Parms = 2 4
In sub3: 2. CCC 3. DDD 4. EEE
In sub3: AAA BBB CCCXX DDDXX EEEXX FFF
In main: Var1 = 51 Var2 = 3 Array1 = AAA BBB CCCXX DDDXX EEEXX FFF
#
SUB4: Pass mixed parameters to
subroutine... Scalar and array types
# The variable "@_" is a
default array of all things passed.
# Demonstrates the difference between
"my" and "local"
sub
sub4
{
my ($var1, @temp); # Variables known only to this subroutine
(preferred)
local (@arr1); # Variable known here as well as all
subroutine calls (rare)
print "
In sub4: Parms = ", @_ ,
" First = ", $_[0],
"\n";
$var1 = 0;
@arr1 = qw (1,2,3,4,5);
sub1;
# The "local" @arr1 will be known to sub1 and not the global
@arr1
$var1 = $_[0];
@temp = @_[1..$#_];
for($i = 0; $i <= $#temp; $i++)
{chop($temp[$i]);
}
print "\n";
$var1 = 99;
print "
In sub4: Changing first parameter - ", $_[0], "\n";
print "
In sub4: Temp = ", @temp, "\n";
return @temp;
}
Calling sub4: @arr1 = sub4( $var1, @arr1 );
In sub4: Parms = 51AAABBBCCCXXDDDXXEEEXXFFF First = 51
In sub1: Var1 = 99 Var2 = 3 Array1 = 1,2,3,4,5
In sub4: Changing first parameter -> 51
In sub4: Temp = AABBCCCXDDDXEEEXFF
In main: Var1 = 51 Var2 = 3 Array1 = AA BB CCCX DDDX EEEX FF
In sub4: Parms = 51AAABBBCCCXXDDDXXEEEXXFFF First = 51
In sub1: Var1 = 99 Var2 = 3 Array1 = 1,2,3,4,5
In sub4: Changing first parameter -> 51
In sub4: Temp = AABBCCCXDDDXEEEXFF
In main: Var1 = 51 Var2 = 3 Array1 = AA BB CCCX DDDX EEEX FF
#
SUB5: Working with references variables.
The backslash, or "\",
will
# send a pointer to a variable. The
"$" dereferences that pointer.
# Note the difference if the backslash is
used inside the print string
# since "\$" prints the dollar
sign character instead.
sub
sub5
{
print "
In sub5: parms = @_ \n";
my($val1) = $_[0];
$arry_ptr = $_[1];
$var2_ptr = $_[2];
print "
In sub5: \$val1 = ", $val1,
"Address = ", \$val1, "\n";
$val1 = $val1 - 1;
print "
In sub5: Var1 = ",
$val1, "\n";
print "
In sub5: Var2 = ",
$var2_ptr, " Contents = ",
$$var2_ptr, "\n";
$$var2_ptr = $$var2_ptr - 1;
print "
In sub5: Variable1 = ",
$var2_ptr, " Contents = ",
$$var2_ptr, "\n";
chop(@$arry_ptr);
print "
In sub5: Array1 = ",
$arry_ptr, " Contents = ",
@$arry_ptr, "\n";
}
Reference values:
In main: Var1 = 51 Pointer = SCALAR(0x80c6cac)
In main: Var2 = 3 Pointer = SCALAR(0x80c6cd0)
In main: Array = AABBCCCXDDDXEEEXFF Pointer = ARRAY(0x80c6d00)
Calling sub5: sub5( $var1, \@arry1, \$var2 );
In sub5: parms = 51 ARRAY(0x80c6d00) SCALAR(0x80c6cd0)
In sub5: $val1 = 51 Address = SCALAR(0x80cde0c)
In sub5: Var1 = 50
In sub5: Var2 = SCALAR(0x80c6cd0) Contents = 3
In sub5: Variable1 = SCALAR(0x80c6cd0) Contents = 2
In sub5: Array1 = ARRAY(0x80c6d00) Contents = ABCCCDDDEEEF
In main: Var1 = 51 Var2 = 2 Array1 = A B CCC DDD EEE F
#
Main starts here:
print
"Initial Values:\n";
print
"In main: Var1 = $var1 Var2 =
$var2 Array1 = @arr1 \n\n";
print
"Calling sub1:\n";
sub1;
print
"In main: Var1 = $var1 Var2 =
$var2 Array1 = @arr1 \n\n";
print
"Calling sub2:\n";
sub2($var2,
88);
print
"In main: Var1 = $var1 Var2 =
$var2 Var3 = $var3 Array1 = @arr1 \n\n";
print
"Calling sub3:\n";
$var2
= sub3(2,4);
print
"In main: Var1 = $var1 Var2 =
$var2 Array1 = @arr1 \n\n";
print
"Calling sub4:\n";
@arr1
= sub4($var1,@arr1);
print
"In main: Var1 = $var1 Var2 =
$var2 Array1 = @arr1 \n\n";
print
"Reference values:\n";
print
"In main: Var1 = ", $var1,
"\t Pointer = ", \$var1, "\n";
print
"In main: Var2 = ", $var2,
"\t Pointer = ", \$var2, "\n";
print
"In main: Array = ", @arr1, "\t Pointer = ",\@arr1,
"\n";
print
"Calling sub5:\n";
sub5($var1,
\@arr1, \$var2);
print
"In main: Var1 = $var1 Var2 =
$var2 Array1 = @arr1 \n\n";
Perl Example #6
Dynamic Web Pages with Perl and CGI
Dynamic Web Pages with Perl and CGI
About
the Program
This Perl example contains two
separate programs. The first one, the "FORM Program", creates
a simple HTML form requesting input from the user. After the "submit"
button is activated, this program will call a second program, the "CALENDAR
Program", which generates a web page containing a calendar for the
requested month and a random graphic loaded from a directory full of JPEG
images.
The FORM Program: form.pl
The FORM Program: form.pl
#!/usr/local/bin/perl
#
This program is just one very long print statement written in Perl.
#
When it is run from the web-server, however, it will send the text
#
between the two EOF markers to a user who has requested the file.
#
That text is standard HTML code that will be displayed properly as
#
a web page by that person's browser.
print
<<EOF;
Content-type:
text/html
<HTML>
<BODY
BGCOLOR=WHITE TEXT=BLACK>
<CENTER>
<H1>
Creating a Dynamic Calendar <br>
with CGI and Perl </H1>
</CENTER>
This
simple web page prints out a form requesting a name and date from
a
user. When the submit button is pressed,
it will call a second Perl
program
that generates a presonalized calendar using that information.
These two Perl Scripts must reside in a
special "<B>CGI</B>"directory
called
<B>cgi-bin</B> which is created as a sub-directory off of
<B>web-docs</B>,
and must have the proper permissions in order for the
pages
to work on the web server. <br>
<p>
|
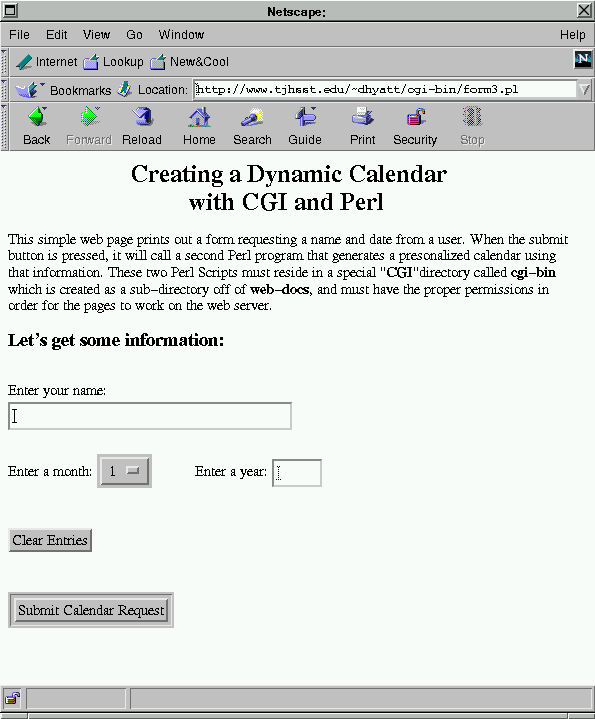
<H3> Let's get some information:</H3>
<FORM METHOD = "GET"
ACTION="answer3.pl">
<br>
Enter your name:<br>
<INPUT TYPE = "TEXT" NAME = "name"
SIZE = "30">
<br>
<br>
Enter a month:
<SELECT NAME = "month"
VALUE="Month" >
<OPTION SELECTED>1
<OPTION>2
<OPTION>3
<OPTION>4
<OPTION>5
<OPTION>6
<OPTION>7
<OPTION>8
<OPTION>9
<OPTION>10
<OPTION>11
<OPTION>12
</SELECT>
Enter a year:
<INPUT TYPE = "TEXT"
NAME =
"year" SIZE = "4">
<br>
<br>
<br>
<INPUT TYPE = "RESET"
NAME =
"reset" VALUE = "Clear Entries">
<br>
<br>
<br>
|
FORM Program Output
 |
<INPUT
TYPE = "SUBMIT" NAME = "submit" VALUE = "Submit
Calendar Request">
<br>
</BODY>
</HTML>
EOF
The CALENDAR Program: calendar.pl
#!/usr/local/bin/perl
#
This includes a library module written by Steven Brenner
#
that allows the use of a nice function called "ReadParse".
require
'/www/cgi/cgi-lib.pl';
#
The function returns a hash of the input from a "CGI form". The
#
hash keys are the variable names identified in that original form.
#
The hash values contain the information submitted by the user.
&ReadParse(%in);
#
The following will make a listing of JPEG images in a parallel
#
directory. The function
"srand" will set a seed for a pseudorandom
#
number generator that will be used later.
The web page will
#
display a random graphic from that directory.
srand; #
Initialize random number seed
$i
= 0;
while
(<../images/*.jpg >) # Loop though all files in other directory
{
$pictures[$i++] = $_; # Make an array of JPEG image names
}
$image
= $pictures[int(rand($i))]; # Select
random file name from set
#
The next routine attempts to solve a serious security problem
#
in this program. If the user enters the
year, followed by a
#
semi-colon, another UNIX command can be put on the same line.
#
After the server finishes running "cal", it will run that other
#
command also. Potentially evil things could happen! The next
#
"if" clause scans through the user's input, and if there is a
#
pattern match for a semi-colon, an alternative page is printed.
|
if ( $in{"year"} =~ ";")
{print <<ERR;
Content-type: text/html
<HTML>
<BODY BGCOLOR=WHITE TEXT=BLACK>
<H3>Hello, $in{"name"}!
No Calendar today...
<br></H3>
<IMG SRC= "$image">
</BODY>
</HTML>
ERR
}
|
|
CALENDAR Output
(Bad Input Value) 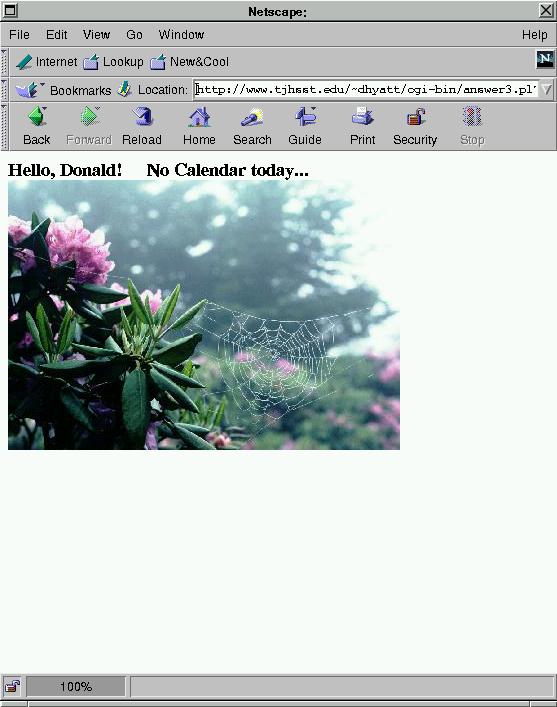 |
#
If the input is "OK", then the "else" clause is
executed. This
#
will run the UNIX command "cal" for the specific month, as well
#
as the full year, and will display the web page.
else{
#
The next few lines concatenates month and year into a single string
#
and use "cal" to generate both monthly and yearly calendars.
$date
= $in{"month"}." ".$in{"year"};
@calendar
= `cal $date`;
@year
= `cal $in{"year"}`;
#
From this point forward, the standard HTML code is printed.
|
print <<EOF;
Content-type: text/html
<HTML>
<BODY BGCOLOR=WHITE TEXT=BLACK>
<H3>Hello, $in{"name"}!
Here's your
monthly calendar...
<br>
</H3>
<TABLE>
<TR>
<TD>
<B>
<PRE>
<FONT COLOR = "#FF0000" SIZE=5>
@calendar
</FONT>
</PRE>
</B>
</TD>
<TD>
<IMG SRC = "$image">
</TD>
</TR>
</TABLE>
<BR>
<FONT SIZE = 4>
The Full Year $in{"year"}
</FONT>
<PRE>
@year
</PRE>
</BODY>
</HTML>
EOF
}
|
CALENDAR Output
(Valid Input ) 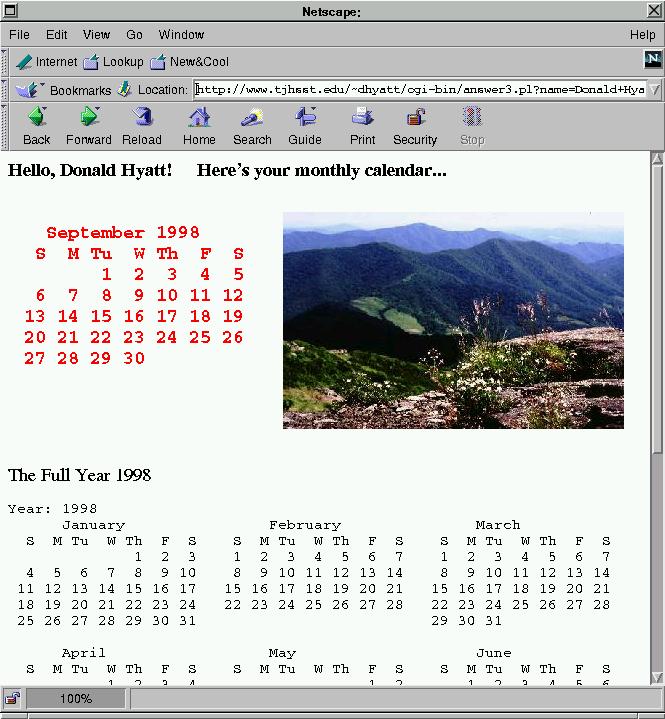 |
Perl Example #7
Working with Strings and Substrings
Working with Strings and Substrings
About
the Program
This program demonstrates some of
the string manipulation capabilities in Perl. It relies on the ability to
determine the index of a substring using the functions index and rindex,
as well as substr that can be used to replace that pattern with
another string.
#!/usr/bin/perl
#
Working with Strings and Substrings
# Using "length" to find the length
of a string
$sentence
= "Perl is great at manipulating strings, naturally.";
$len
= length $sentence;
print
"$sentence \n";
print
"This string is $len characters long.\n\n";
Perl is great at manipulating strings, naturally.
This string is 49 characters long.
#
Using "index" to find a substring
which returns the position
# of some substring, or -1 if it is not found
there.
#
Command Format: $x = index ($bigstring,
$littlestring);
$word
= "Perl";
$where
= index( $sentence, $word);
print
"$sentence \n";
print
"$word begins at character $where \n\n";
Perl is great at
manipulating strings, naturally.
Perl begins at character 0
Perl begins at character 0
$word
= "great";
$where
= index( $sentence, $word);
print
"$sentence \n";
print
"$word begins at character $where \n\n";
Perl is great at
manipulating strings, naturally.
great begins at character 8
great begins at character 8
$word
= "xxx";
$where
= index( $sentence, $word);
print
"$sentence \n";
print
"$word begins at character $where \n\n";
Perl is great at
manipulating strings, naturally.
xxx begins at character -1
xxx begins at character -1
#
Using "rindex" to find rightmost index
$word
= "ing";
$where
= index( $sentence, $word);
print
"$sentence \n";
print
"The first $word begins at character $where \n";
$where
= rindex( $sentence, $word);
print
"The last $word begins at character $where \n\n";
Perl is great at
manipulating strings, naturally.
The first ing begins at character 26
The last ing begins at character 33
The first ing begins at character 26
The last ing begins at character 33
#
Using the optional third parameter to "index"
#
Commmand Format: $x = index($bigstring,
$littlestring, $skip);
#
Commmand Format: $x = rindex($bigstring,
$littlestring, $before);
$word
= "at";
$first
= index($sentence, $word);
$last
= rindex($sentence, $word);
print
"$sentence \n";
print
"The index of the first $word is $first and the final index is
$last\n";
$next
= index( $sentence, $word, $first+1);
print
"After $first characters, the index of the next $word is $next \n";
$previous
= rindex( $sentence, $word, $last-1);
print
"After $last characters, the index of the previous $word is $previous
\n\n";
Perl is great at
manipulating strings, naturally.
The index of the first at is 11 and the final index is 40
After 11 characters, the index of the next at is 14
After 40 characters, the index of the previous at is 24
The index of the first at is 11 and the final index is 40
After 11 characters, the index of the next at is 14
After 40 characters, the index of the previous at is 24
#
Extracting and Replacing Substrings
#
Command Format: $s = substr( $string,
$start, $length);
#
This grabs a substring
$grab
= substr( $sentence, 5, 8);
print
"$sentence \n";
print
"Grabbed Pattern: $grab starts at 5 and goes 8 chars \n\n";
Perl is great at
manipulating strings, naturally.
Grabbed Pattern: is great starts at 5 and goes 8 chars
Grabbed Pattern: is great starts at 5 and goes 8 chars
#
This replaces a substring
$replacement
= "is totally awesome";
substr($sentence,
5, 8) = $replacement;
print
"Substituting $replacement staring at 5 and going 8 chars \n";
print
"$sentence \n\n";
Substituting is totally
awesome staring at 5 and going 8 chars
Perl is totally awesome at manipulating strings, naturally.
Perl is totally awesome at manipulating strings, naturally.
Perl Example #8
Simple Data Structures
Simple Data Structures
About
the Program
This program shows several
techniques available in Perl for creating some standard data structures covered
in Advanced Placement Computer Science. It includes an implementation of a stack,
a queue, and three methods for generating a linked list.
The first linked list is generated using a two-dimensional array, the second
uses reference variables or pointers, and the third uses a hash.
#!/usr/bin/perl
##
Simple Data Structures
#
A Stack
print
"Making a Stack\n";
@stack
= qw( awk bash chmod );
print
"Initial stack:\n @stack \n";
push
(@stack, "diff");
print
"Push item on stack:\n @stack
\n";
$item
= "Emacs";
push
(@stack, $item);
print
"Push item on stack:\n @stack
\n";
$top
= pop @stack;
print
"Popping top of stack:
$top\n";
print
"Final stack:\n @stack \n\n";
Making a Stack
Initial stack:
awk bash chmod
Push item on stack:
awk bash chmod diff
Push item on stack:
awk bash chmod diff Emacs
Popping top of stack: Emacs
Final stack:
awk bash chmod diff
Initial stack:
awk bash chmod
Push item on stack:
awk bash chmod diff
Push item on stack:
awk bash chmod diff Emacs
Popping top of stack: Emacs
Final stack:
awk bash chmod diff
#
A Queue
print
"Making a \"First In First Out\" Queue\n";
@queue
= qw( lpr mcopy ps );
print
"Initial queue:\n @queue \n";
unshift(@queue,
"kill");
print
"Add item to queue:\n @queue
\n";
$item
= "df";
unshift(@queue,
$item);
print
"Add item to queue:\n @queue
\n";
$fifo
= pop @queue;
print
"Remove FIFO item: $fifo\n";
print
"Final queue:\n @queue \n\n";
Making a "First In
First Out" Queue
Initial queue:
lpr mcopy ps
Add item to queue:
kill lpr mcopy ps
Add item to queue:
df kill lpr mcopy ps
Remove FIFO item: ps
Final queue:
df kill lpr mcopy
Initial queue:
lpr mcopy ps
Add item to queue:
kill lpr mcopy ps
Add item to queue:
df kill lpr mcopy ps
Remove FIFO item: ps
Final queue:
df kill lpr mcopy
#
Linked Lists
print
"Making Linked Lists\n";
##
Method #1 using 2D Arrays
sub
print_list {
$max = $_[0];
for ($i=0; $i<$max; $i++)
{
print "$i. $list[$i][0]\t $list[$i][1]\n";
}
}
#
Declaring a 2-D Array, which is just an array of 1-D arrays
@list
= ( ["vi ",
"Null"], ["emacs", "Null"], ["joe ", "Null" ]);
$max
= $#list + 1;
print
"Initial Values\n";
print_list($max);
print
"\n\n";
Making Linked Lists
Initial Values
0. vi Null
1. emacs Null
2. joe Null
Initial Values
0. vi Null
1. emacs Null
2. joe Null
#
Create Some Links
$list[0][1]
= 2;
$list[2][1]
= 1;
print
"Made Links\n";
print_list($max);
print
"\n\n";
Made Links
0. vi 2
1. emacs Null
2. joe 1
0. vi 2
1. emacs Null
2. joe 1
$next
= 0;
#Step
through Linked List
print
"Traversing list:\n";
while
($next !~ "Null"){
print "$list[$next][0] \n";
$next = $list[$next][1];
}
print
"\n\n";
Traversing list:
vi
joe
emacs
vi
joe
emacs
##
Method #2 Reference Variables, or
Pointers
@links
= qw( 2 Null 1);
print
"Using Pointers\n";
@nodes
= qw (finger:Null whois:Null who:Null);
for
($i = 0; $i <= $#nodes; $i++)
{ $ptr = \$nodes[$i];
@data = split(/:/,$$ptr);
print "Before: $ptr
@data ";
$data[1] = $links[$i];
print "-> @data \n";
$$ptr = join ':',@data;
}
print
"\n\n";
Using Pointers
Before: SCALAR(0x80d2168) finger Null -> finger 2
Before: SCALAR(0x80d2174) whois Null -> whois Null
Before: SCALAR(0x80d2180) who Null -> who 1
Before: SCALAR(0x80d2168) finger Null -> finger 2
Before: SCALAR(0x80d2174) whois Null -> whois Null
Before: SCALAR(0x80d2180) who Null -> who 1
print
"@nodes";
print
"\n\n";
finger:2
whois:Null who:1
print
"Traversing list:\n";
$next
= 0;
while
($next !~ "Null")
{@data = split(":",$nodes[$next]);
print $data[0], "\n";
$next = $data[1];
}
print
"\n\n";
Traversing list:
finger
who
whois
finger
who
whois
##
Method #3 - Using a Hash
print
"Using a Hash\n";
#
Initializing a hash using the "correspond" operator to make easy
reading
%hash
= (
"man" => "Get UNIX Help:more",
"cat" => "Display
Files:Null",
"more"=> "Page
Through Files:cat");
print
"Traversing list:\n";
$next
= "man";
while
($next !~ "Null")
{ @data = split(/:/, $hash{$next});
print "$next $data[0] \n";
$next = $data[1];
}
print "\n\n";
Using a Hash
Traversing list:
man Get UNIX Help
more Page Through Files
cat Display Files
Traversing list:
man Get UNIX Help
more Page Through Files
cat Display Files
Perl Example #9
Classes, Objects, and Perl Modules
Classes, Objects, and Perl Modules
About
the Program
This program demonstrates how to
define a class called Student, with its associated methods or functions.
These routines are defined in an external Perl Module called StudentRec.pm.
The regular program, ex9.pl,
sets up an array of record-like structures. The Constructor for this class
calls the method new, which establishes a reference to an object of the
class type. The function new then calls initialize which either
assigns initial values that were passed as parameters, or else assigns default
values. Later, elements in the array are modified using the method Modify,
or printed using PrintRec.
The typical output one would expect
is printed in red. A few additonal lines of output, printed in blue, are used
to better understand what is happening in the Perl Module. Such debugging
output would not normally appear in the final program.
The
External Perl Module: StudentRec.pm
package
Student; # Class Definition for Object
of type Student
@student_data
= qw(Name ID GPA ); # Name the fields
###
The subroutines "new" and "initialize" for the Constructor
sub
new
{
print "new: @_ \n";
my $class_name = shift; # Gets class name from parmlist
my $recref = {}; # Creates reference to object
bless $recref, $class_name; # Associates reference with class
$recref -> initialize(@_); # Call local initialize subroutine
# passing rest of parmlist
return $recref; # Explicit return of value of
$recref
}
sub
initialize
{
print "initialize: @_ \n";
my $stu_ref = shift; # Receive an object reference as 1st param
my %parms = @_; # Get passed parameters from the call
to "new"
# Change hash reference for key with
supplied value, or assign default
$stu_ref -> {'Name'} = $parms{'Name'} ||
"NOBODY";
$stu_ref -> {'ID'} = $parms{'ID'} ||
"NO_ID";
$stu_ref -> {'GPA'} = $parms{'GPA'} ||
0;
}
sub
PrintRec # Print a student record
{
print "PrintRec: @_ \n";
my $instance = shift; # Figure out who I am
for(@student_data) # Go through all fields
{
print "$_: ",
$instance -> {$_}, "\n"; # Print key and value
}
}
sub
Modify #
Modify student Record
{
print "Modify: @_ \n";
my $instance = shift; # Figure out who
I am
my %parms = @_; # Make hash out of rest of parm list
# Step through all keys in parm list
for(keys %parms)
{
$instance -> {$_} = $parms{$_};
# Replace with new value
}
}
1; # Return 1 to say Perl Module
loaded correctly
The Program:
ex9.pl
#!/usr/bin/perl
-w
###
This program deals with an array of records.
The records are objects
###
of type Student, which are defined in Perl Module called StudentRec.pm
require
StudentRec; # Allows program to use
items defined in Perl Module
###
subroutine to print out records in an Array
sub
print_kids
{
my $kid;
foreach $kid (@person)
{
PrintRec $kid; # Call method "PrintRec" defined
for class Student
print "\n";
}
}
####
Initialize Array of Records ####
## Method "new" creates an object of
type Student, and then passes
## parameters onto an initialization routine. One would usually
## initialize from a file rather than direct
assignment, however.
#
This Record is defined in typical order (Name, ID, GPA)
$person[0]
= new Student( 'Name' => "Bill",
'ID' => "12-345-6",
'GPA' =>
3.8);
#
No fields are defined for this record - Constructor uses defaults
$person[1]
= new Student;
#
Fields may be defined in any order since the record is a hash
$person[2]
= new Student( 'GPA' => 4.0,
'Name' => "Hillary",
'ID' => "98-765-4");
new: Student Name Bill ID 12-345-6 GPA 3.8
initialize: Student=HASH(0x10023180) Name Bill ID 12-345-6 GPA 3.8
new: Student
initialize: Student=HASH(0x10023198)
new: Student GPA 4 Name Hillary ID 98-765-4
initialize: Student=HASH(0x100231b0) GPA 4 Name Hillary ID 98-765-4
#
Print out details
print
"Before...\n";
print_kids;
Before...
PrintRec: Student=HASH(0x10023180)
Name: Bill
ID: 12-345-6
GPA: 3.8
PrintRec: Student=HASH(0x10023198)
Name: NOBODY
ID: NO_ID
GPA: 0
PrintRec: Student=HASH(0x100231b0)
Name: Hillary
ID: 98-765-4
GPA: 4
####
Change things a bit ####
#
Add new person. Undefined fields take the default values
$person[3]
= new Student('Name' => "Monica");
#
Call Modify method in package
$person[0]
-> Modify('GPA' => 1.6); # Pass key and value in parm list
new: Student Name Monica
initialize: Student=HASH(0x10023210) Name Monica
Modify: Student=HASH(0x10023180) GPA 1.6
print
"After...\n";
print_kids;
After...
PrintRec: Student=HASH(0x10023180)
Name: Bill
ID: 12-345-6
GPA: 1.6
PrintRec: Student=HASH(0x10023198)
Name: NOBODY
ID: NO_ID
GPA: 0
PrintRec: Student=HASH(0x100231b0)
Name: Hillary
ID: 98-765-4
GPA: 4
PrintRec: Student=HASH(0x10023210)
Name: Monica
ID: NO_ID
GPA: 0
Perl Example #10
More on Pattern Matching
And Regular Expressions
More on Pattern Matching
And Regular Expressions
About
the Program
This program demonstrates additional
examples of pattern matching and substitution operations using regular
expressions. Some of the more common regular expression
"metacharacters" used for pattern matching are outlined in the charts
below.
|
|
#!/usr/bin/perl
-w
###
More on Regular Expressions ###
###
Pattern Matching ###
sub
print_array # Print the full
contents of the Array
{
for ($i=0; $i<=$#strings;$i++)
{print $strings[$i], "\n";
}
print
"\n\n";
}
sub
grep_pattern # Print strings which
contain the pattern
{
foreach (@strings)
{print "$_\n" if /$pattern/;
}
print
"\n\n";
}
###
Setting up the Array of strings
@strings
= ("Two, 4, 6, Eight", "Perl is cryptic", "Perl is
great");
@strings[3..6]
= ("1, Three", "Five, 7", "Write in Perl",
"Programmer's heaven");
print_array;
Two, 4, 6, Eight
Perl is cryptic
Perl is great
1, Three
Five, 7
Write in Perl
Programmer's heaven
Perl is cryptic
Perl is great
1, Three
Five, 7
Write in Perl
Programmer's heaven
##
Find the word "Perl"
$pattern
= 'Perl';
print
"Searching for: $pattern\n";
grep_pattern;
Searching for: Perl
Perl is cryptic
Perl is great
Write in Perl
Perl is cryptic
Perl is great
Write in Perl
##
Find "Perl" at the beginning of a line
$pattern
= '^Perl';
print
"Searching for: $pattern\n";
grep_pattern;
Searching for: ^Perl
Perl is cryptic
Perl is great
Perl is cryptic
Perl is great
##
Find sentences that contain an "i"
$pattern
= 'i';
print
"Searching for: $pattern\n";
grep_pattern;
Searching for: i
Two, 4, 6, Eight
Perl is cryptic
Perl is great
Five, 7
Write in Perl
Two, 4, 6, Eight
Perl is cryptic
Perl is great
Five, 7
Write in Perl
##
Find words starting in "i", i.e. a space preceeds the letter
$pattern
= '\si';
print
"Searching for: $pattern\n";
grep_pattern;
Searching for: \s i
Perl is cryptic
Perl is great
Write in Perl
Perl is cryptic
Perl is great
Write in Perl
##
Find strings containing a digit
$pattern
= '\d';
print
"Searching for: $pattern\n";
grep_pattern;
Searching for: \d
Two, 4, 6, Eight
1, Three
Five, 7
Two, 4, 6, Eight
1, Three
Five, 7
##
Search for a digit followed by some stuff
$pattern
= '\d+.+';
print
"Searching for: $pattern\n";
grep_pattern;
Searching for: \d+ .+
Two, 4, 6, Eight
1, Three
Two, 4, 6, Eight
1, Three
##
Find strings with a digit at the end of a line
$pattern
= '\d+$';
print
"Searching for: $pattern\n";
grep_pattern;
Searching for: \d+ $
Five, 7
Five, 7
##
Search for a digit, possible stuff in between, and another digit
$pattern
= '\d.*\d';
print
"Searching for: $pattern\n";
grep_pattern;
Searching for: \d .* \d
Two, 4, 6, Eight
Two, 4, 6, Eight
##
Find four-letter words, i.e. four characters offset by word boundaries
$pattern
= '\b\w{4}\b';
print
"Searching for: $pattern\n";
grep_pattern;
Searching for: \b \w{4}
\b
Perl is cryptic
Perl is great
Five, 7
Write in Perl
Perl is cryptic
Perl is great
Five, 7
Write in Perl
##
Sentences with three words, three word fields separated by white space
$pattern
= '\w+\s+\w+\s+\w+';
print
"Searching for: $pattern\n";
grep_pattern;
Searching for: \w+ \s+
\w+ \s+ \w+
Perl is cryptic
Perl is great
Write in Perl
Perl is cryptic
Perl is great
Write in Perl
##
Find sentences with two "e" letters, and possible stuff between
$pattern
= 'e.*e';
print
"Searching for: $pattern\n";
grep_pattern;
Searching for: e .* e
Perl is great
1, Three
Write in Perl
Programmer's heaven
Perl is great
1, Three
Write in Perl
Programmer's heaven
####
Marking Regular Expression Sub-strings and Using Substitution
##
Substitute "Pascal" for "Perl" words at the beginning of a
line
print
"Substituting first Perl words.\n";
foreach(@strings)
{s/^Perl/Pascal/g;
}
print_array;
Substituting first Perl
words.
Two, 4, 6, Eight
Pascal is cryptic
Pascal is great
1, Three
Five, 7
Write in Perl
Programmer's heaven
Two, 4, 6, Eight
Pascal is cryptic
Pascal is great
1, Three
Five, 7
Write in Perl
Programmer's heaven
##
Find five-letter words and replace with "Amazing"
$pattern
= '\b\w{5}\b';
print
"Searching for: $pattern\n";
foreach(@strings)
{s/$pattern/Amazing/;
}
print_array;
Searching for: \b \w{5}
\b
Two, 4, 6, Amazing
Pascal is cryptic
Pascal is Amazing
1, Amazing
Five, 7
Amazing in Perl
Programmer's heaven
Two, 4, 6, Amazing
Pascal is cryptic
Pascal is Amazing
1, Amazing
Five, 7
Amazing in Perl
Programmer's heaven
##
Replace any "Perl" words at the end of a line with "Cobol"
print
"Substituting Final Perl \n";
foreach(@strings)
{s/Perl$/Cobol/;
}
print_array;
Substituting Final Perl
Two, 4, 6, Amazing
Pascal is cryptic
Pascal is Amazing
1, Amazing
Five, 7
Amazing in Cobol
Programmer's heaven
Two, 4, 6, Amazing
Pascal is cryptic
Pascal is Amazing
1, Amazing
Five, 7
Amazing in Cobol
Programmer's heaven
##
Delete any apostrophes followed by an "s"
print
"Substituting null strings\n";
foreach(@strings)
{s/\'s//;
# Replace with null string
}
print_array;
Substituting null strings
Two, 4, 6, Amazing
Pascal is cryptic
Pascal is Amazing
1, Amazing
Five, 7
Amazing in Cobol
Programmer heaven
Two, 4, 6, Amazing
Pascal is cryptic
Pascal is Amazing
1, Amazing
Five, 7
Amazing in Cobol
Programmer heaven
##
Search for two digits in same line, and switch their positions
print
"Tagging Parts and Switching Places\n";
foreach(@strings)
{ $pattern = '(\d)(.*)(\d)';
if (/$pattern/)
{ print "Grabbed pattern:
$pattern \$1 = $1 \$2 = $2
\$3 = $3\n";
s/$pattern/$3$2$1/;
}
}
print
"\n";
print_array;
Tagging Parts and
Switching Places
Grabbed pattern: (\d) (.*) (\d) $1 = 4 $2 = , $3 = 6
Two, 6, 4, Amazing
Pascal is cryptic
Pascal is Amazing
1, Amazing
Five, 7
Amazing in Cobol
Programmer heaven
Grabbed pattern: (\d) (.*) (\d) $1 = 4 $2 = , $3 = 6
Two, 6, 4, Amazing
Pascal is cryptic
Pascal is Amazing
1, Amazing
Five, 7
Amazing in Cobol
Programmer heaven
##
Marking Patterns and using multiple times
print
"Expanding Patterns, and apply more than once in the same line\n";
foreach(@strings)
{ $pattern = '(\d)';
if (/$pattern/)
{
s/$pattern/$1$1$1/g;
}
}
print
"\n";
print_array;
Expanding Patterns, and
apply more than once in the same line
Two, 666, 444, Amazing
Pascal is cryptic
Pascal is Amazing
111, Amazing
Five, 777
Amazing in Cobol
Programmer heaven
Two, 666, 444, Amazing
Pascal is cryptic
Pascal is Amazing
111, Amazing
Five, 777
Amazing in Cobol
Programmer heaven
##
Marking things between word boundaries.
Using part of pattern
print
"Replacing words that end with n \n";
foreach(@strings)
{ $pattern = '\b(\w*)n\b';
if (/$pattern/)
{ print "Grabbed pattern:
$pattern \$1 = $1 \n";
s/$pattern/$1s/;
}
}
print
"\n";
print_array;
Replacing words that end
with n
Grabbed pattern: \b (\w*) n \b $1 = i
Grabbed pattern: \b (\w*) n \b $1 = heave
Two, 666, 444, Amazing
Pascal is cryptic
Pascal is Amazing
111, Amazing
Five, 777
Amazing is Cobol
Programmer heaves
Grabbed pattern: \b (\w*) n \b $1 = i
Grabbed pattern: \b (\w*) n \b $1 = heave
Two, 666, 444, Amazing
Pascal is cryptic
Pascal is Amazing
111, Amazing
Five, 777
Amazing is Cobol
Programmer heaves
##
Sentences with three words, add "n't" after the middle word
$pattern
= '(\w+\s+)(\w+)(\s+\w+)';
print
"Searching for: $pattern\n";
foreach(@strings)
{
s/$pattern/$1$2n\'t$3/;
}
print_array;
Searching for: (\w+
\s+) (\w+) (\s+ \w+)
Two, 666, 444, Amazing
Pascal isn't cryptic
Pascal isn't Amazing
111, Amazing
Five, 777
Amazing isn't Cobol
Programmer heaves
Two, 666, 444, Amazing
Pascal isn't cryptic
Pascal isn't Amazing
111, Amazing
Five, 777
Amazing isn't Cobol
Programmer heaves
##
Sentences with either an "o" or an "e" in them
$pattern
= '[oe]';
print
"Searching for: $pattern\n";
foreach(@strings)
{
s/$pattern/x/g; # The "g" modifyer means
"global", or replace all
} # occurrences of the
"o" or "e" found on that line.
print_array;
Searching for: [oe]
Twx, 666, 444, Amazing
Pascal isn't cryptic
Pascal isn't Amazing
111, Amazing
Fivx, 777
Amazing isn't Cxbxl
Prxgrammxr hxavxs
Twx, 666, 444, Amazing
Pascal isn't cryptic
Pascal isn't Amazing
111, Amazing
Fivx, 777
Amazing isn't Cxbxl
Prxgrammxr hxavxs



0 comments:
Post a Comment